As anyone who has ever worked with me will attest, I love using CROSS APPLY; it’s by far my favorite feature of the SQL language. When used carefully, it can even be more efficient than more traditional methods for aggregating data. This post demonstrates two use-cases where CROSS APPLY is more efficient.
Sample Case
For this lab, I have created a sample database for tracking issues. It’s not very good, I wouldn’t use it, but it has the basic elements needed for my examples to work. To ensure an adequate sample size for performance comparison, I generated 1,250,000 issues across 500 projects of varying issue types and statuses.
Before I continue, I have to make special mention about how I generated this data by using a technique invented by Itzik Ben-Gan. This is the most efficient method for generating a table of sequential numbers, and it’s truly incredible to behold. If you want to read more about how it works and the special optimizations he made, he explains everything in this blog post.
Below is the code to generate the tables and load them with the sample data. You should run this script in a newly created database.
DROP TABLE IF EXISTS dbo.Issues;
DROP TABLE IF EXISTS dbo.IssueStatuses;
DROP TABLE IF EXISTS dbo.IssueTypes;
DROP TABLE IF EXISTS dbo.Projects;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
-- this is a really cool way to generate a table of sequential numbers.
-- Itzik Ben-Gan came up with this technique
CREATE OR ALTER FUNCTION dbo.GetNums(@n AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS(SELECT c FROM (VALUES(1), (1)) AS l(c)),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT TOP (@n) n FROM Nums ORDER BY n;
GO
CREATE TABLE dbo.Projects (
ProjectKey VARCHAR(20) NOT NULL PRIMARY KEY
);
INSERT dbo.Projects
SELECT CONCAT('PROJECT-', CAST(n AS VARCHAR))
FROM dbo.GetNums(500);
CREATE TABLE dbo.IssueTypes (
IssueType VARCHAR(20) NOT NULL PRIMARY KEY
);
INSERT dbo.IssueTypes
VALUES ('TASK')
, ('BUG')
, ('REQUEST')
, ('SUGGESTION')
, ('STORY');
CREATE TABLE dbo.IssueStatuses (
IssueStatus VARCHAR(20) NOT NULL PRIMARY KEY
);
INSERT dbo.IssueStatuses
VALUES ('NEW')
, ('OPEN')
, ('DONE')
, ('CLOSED')
, ('CANCELED');
CREATE TABLE dbo.Issues (
ProjectKey VARCHAR(20) NOT NULL FOREIGN KEY REFERENCES dbo.Projects(ProjectKey)
, IssueKey VARCHAR(40) NOT NULL
, IssueType VARCHAR(20) NOT NULL FOREIGN KEY REFERENCES dbo.IssueTypes(IssueType)
, IssueStatus VARCHAR(20) NOT NULL FOREIGN KEY REFERENCES dbo.IssueStatuses(IssueStatus)
, CreateDate DATETIME2(3) NOT NULL
, PRIMARY KEY (ProjectKey, IssueKey)
);
WITH i AS (
SELECT ProjectKey
, IssueType
, IssueStatus
, CONCAT(IssueType, '-', CAST(IssueNum AS VARCHAR)) AS IssueKey
, n
, ROW_NUMBER() OVER(ORDER BY NEWID()) AS RandomSecond -- A random offset in seconds so that all the issues have different creation dates
FROM dbo.Projects
CROSS JOIN dbo.IssueTypes
CROSS JOIN (
SELECT IssueStatus
, n
, ROW_NUMBER() OVER(ORDER BY n) AS IssueNum
FROM dbo.IssueStatuses
CROSS JOIN dbo.GetNums(100)
) AS issues
)
INSERT dbo.Issues
SELECT ProjectKey
, IssueKey
, IssueType
, IssueStatus
, DATEADD(SECOND, SUM(RandomSecond) OVER (PARTITION BY ProjectKey, IssueType, IssueStatus ORDER BY n), {d'2017-01-01'}) AS CreateDate
FROM i;
-- Defragment the clustered index
ALTER TABLE dbo.Issues REBUILD;
-- Index for latest create date sample
CREATE INDEX [Issues$ProjectKey$CreateDate]
ON dbo.Issues(ProjectKey, CreateDate)
INCLUDE (IssueType, IssueStatus);
-- Index for top 5 open bugs sample
CREATE INDEX [Issues$ProjectKey$IssueType$CreateDate_OpenIssues]
ON dbo.Issues(ProjectKey, IssueType, CreateDate)
INCLUDE (IssueStatus)
WHERE IssueStatus IN ('NEW', 'OPEN');
GO
Depending on the class of machine you are running on this could take several minutes. It took about 45 seconds to run on my machine.
Examples
Now that you have sample data to work with let’s do some test cases and compare performance. Make sure you turn statistics time and IO on.
SET STATISTICS IO ON; SET STATISTICS TIME ON;
Scenario 1: Getting the last issue creation date for each project
This test case makes use of an index we created earlier:
CREATE INDEX [Issues$ProjectKey$CreateDate] ON dbo.Issues(ProjectKey, CreateDate) INCLUDE (IssueType, IssueStatus);
Here is a typical example of how to get the results:
-- Get latest create date by project SELECT ProjectKey , MAX(CreateDate) AS LatestCreateDate FROM dbo.Issues AS i GROUP BY ProjectKey ORDER BY LatestCreateDate DESC OPTION (MAXDOP 1);
It seems pretty straight-forward. We’re getting ProjectKey and MAX(CreateDate) grouped by the ProjectKey. Let’s check out the execution plan:
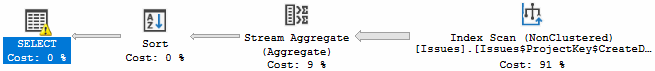
So here it’s scanning an index because it needs to read down all the rows to find the max CreateDate. Fortunately we created an index on ProjectKey and CreateDate so we avoid having to do a sort before the stream aggregate. Let’s look at the statistics:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Issues'. Scan count 1, logical reads 8439, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. CPU time = 297 ms, elapsed time = 293 ms.
That’s pretty much what we should expect. It scanned the index so the read IO will be however many pages comprise the index.
If we could be more selective about how we go after the data we could save a lot of work. It turns out we can, CROSS APPLY to the rescue!
-- Get latest create date by project SELECT ProjectKey , LatestCreateDate FROM dbo.Projects AS p CROSS APPLY ( SELECT TOP (1) CreateDate AS LatestCreateDate , IssueKey FROM dbo.Issues AS i WHERE i.ProjectKey = p.ProjectKey ORDER BY CreateDate DESC ) AS i ORDER BY LatestCreateDate DESC OPTION (MAXDOP 1);
Okay, let me explain what is going on. We are starting with the Projects table and for each row applying the table expression in the sub-query where the ProjectKey is the same. We sort the issues by CreateDate DESC and get the top 1 row. This is actually more efficient because we are being more selective by using the ProjectKey and we can seek to the issue with the latest date. Let’s see the plan:

The real payout is in the statistics:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Issues'. Scan count 500, logical reads 1593, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Projects'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. CPU time = 16 ms, elapsed time = 2 ms.
We saved 6842 in read IO and 291 ms in total time to get the same results. And the reason is because the actual number of projects is very small (500 projects) compared to the amount of issues (1,250,000 issues) and that’s important for another reason. The first example gets more expensive as we add more issues, the second as we add more projects. Since we can expect the ratio between issues and projects to always be very large (the test case creates about 48,000 issues and 190 projects every year) this technique will always be cheaper.
Scenario 2: Getting the top 5 oldest open bugs for each project
This test case makes use of another index we created earlier:
CREATE INDEX [Issues$ProjectKey$IssueType$CreateDate_OpenIssues]
ON dbo.Issues(ProjectKey, IssueType, CreateDate)
INCLUDE (IssueStatus)
WHERE IssueStatus IN ('NEW', 'OPEN');
This time we are using a filtered index for new and open issues. We could have also filtered for this example IssueType = ‘BUG’ but I didn’t include it so it could be used for any issue type.
Let’s look at one approach to this problem:
-- Get top 5 oldest open bugs by project
WITH ranked AS (
SELECT ProjectKey
, CreateDate
, IssueKey
, IssueStatus
, ROW_NUMBER() OVER(PARTITION BY ProjectKey ORDER BY CreateDate) AS RowNum
FROM dbo.Issues
WHERE IssueType = 'BUG'
AND IssueStatus IN ('NEW', 'OPEN')
)
SELECT ProjectKey
, CreateDate
, IssueKey
, IssueStatus
FROM ranked
WHERE RowNum < 6
ORDER BY ProjectKey, CreateDate
OPTION (MAXDOP 1);
So, what is going on here? Basically for each ProjectKey we are ranking issues by ordr of the CreateDate and then filtering the issues that have a rank less than 6. Let’s see the plan.
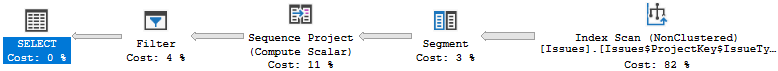
We are being more selective (IssueType = ‘BUG’) and the filtered index is smaller, but we still need to scan this index to compute the rank. Here’s the stats:
Table 'Issues'. Scan count 1, logical reads 3287, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. CPU time = 62 ms, elapsed time = 135 ms.
Once again, CROSS APPLY saves the day!
-- Get top 5 oldest open bugs by project
SELECT ProjectKey
, CreateDate
, IssueKey
, IssueStatus
FROM dbo.Projects AS p
CROSS APPLY (
SELECT TOP (5) CreateDate
, IssueKey
, IssueStatus
FROM dbo.Issues AS i
WHERE i.ProjectKey = p.ProjectKey
AND IssueType = 'BUG'
AND IssueStatus IN ('NEW', 'OPEN')
ORDER BY CreateDate
) AS i
ORDER BY ProjectKey, CreateDate
OPTION (MAXDOP 1);
This is very similar to the previous CROSS APPLY example and works exactly the same way. The additional benefit here is with the TOP (5) and ORDER BY CreateDate we are able to short-circuit the results once we have reached the 5th ranked bug which we are unable to do using the other method. Here’s the plan:

And the statistics:
Table 'Issues'. Scan count 500, logical reads 1632, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Projects'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. CPU time = 0 ms, elapsed time = 101 ms.
Conclusions
The first thing we can conclude is that I am far too obsessive about using CROSS APPLY (I didn’t even talk about CROSS APPLY vs UNPIVOT) and I should probably stop trying to fit it into every query I write. Even so, there are certain circumstances where CROSS APPLY have significantly better performance – as long as the row-count ratio between the applied table to the grouping table is very large and you can deploy the right indexes.